
I have been wanting to find a way to describe various forces and challenges we can apply when testing. One of the scales that appealed to me is the Beaufort Scale which is used to assess and communicate wind speeds based on observation (rather than precision). I propose we could use a similar scale for the test conditions we want to use when testing software and computer systems.
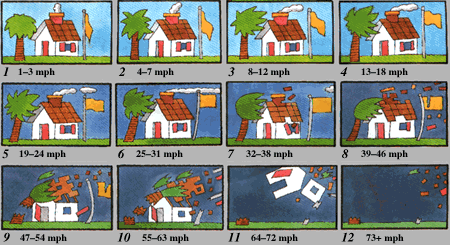
Beaufort Scale Illustration (from gcaptain.com)
Source gcaptain.com
What would I like to achieve by creating the scale?
What would I like to achieve when applying various scales as part of testing software and systems?
- Devise ways to test software and systems at various values on the scale so we learn enough about the behaviours to make useful decisions we’re unlikely to regret.
Testing Beaufort Scale
Here is my initial attempt at describing a Testing Beaufort Scale:
- Calm: there’s nothing to disturb or challenge the software. Often it seems that much of the scripted testing that’s performed is done when the system is calm, nothing much else is happening, simply testing at a gentle, superficial level. (for the avoidance of doubt the tester may often be stressed doing such boring testing :P)
- Light Air:
- Gentle Breeze:
- Gale:
- Hurricane: The focus changes from continuing to operate to one that protects the safety and integrity of the system and data. Performance and functionality may be reduced to protect and enable essential services to be maintained/sustained while the forces are in operation.
Some examples
- Network outages causing sporadic data loss
- Database indexes cause slow performance and processing delays
- Excessive message logging
- Long running transactions (somewhat longer, or orders of magnitude longer).
- Heavy workloads?
- Loss and/or corruption in data, databases, indices, caches, etc.
- Controlled system failover: instigated by humans where the failover is planned and executed according to the plan – here the focus isn’t on the testing the failover it’s on testing the systems and applications that use the resource that’s being failed-over.
- Denial-of-Service: Service is denied when demand significantly exceeds the available supply. Often this is of system and service resources. Denials-of-Service exist when external attackers flood systems with requests. They can also exist when a system is performing poorly (for instance while running heavy-duty backups, updates, when indexes are corrupt or not available, etc. etc. Another source is when upstream server(s) unavailable causing queues to build and fill up which puts pressure on handling requests from users or other systems and services. c.f. resource exhaustion.
- In-flight configuration changes e.g. changing IP address, routing, database tables, system patching, …
- n Standard Deviations from ‘default’ or ‘standard’ configurations of systems and software. The further the system is from a relatively well known ‘norm’ the more likely it may behave in unexpected and sometimes undesirable ways. e.g. if a server is set to restart every minute, or only once every 5 years instead of every week (for instance) how does it cope, how does it behave, and how does its behaviour affect the users (and peers) of the server? Example: a session timeout of 720 minutes vs the default of 30 minutes.
- Special characters in parameters or values, as can atypical values. c.f. data as code
- Permission mismatches, abuses, and mal-configurations
- Resource constraints may limit the abilities of a system to work, adapt and respond.
- Increased latencies:
- Unexpected system failover
- Unimagined load (note: not unimaginable load or conditions, simply what the tester didn’t envisage might be the load under various conditions)
What to consider measuring
Detecting the effects on the system… Can we define measures and boundaries (similar to equivalence partitions).
Lest we forget
From a broader perspective our work and our focus is often affected by the mood of customers, bosses, managers and stakeholders. These may raise our internal Beaufort Scale and adversely affect our ability to focus on our testing. Paradoxically being calm when the situation is challenging is a key success factor in achieving our mission and doing good work.
Cardboard systems and chocolate soldiers
Further reading
An attractive poster of the Beaufort Scale including how to set the sails on a sailing boat http://www.web-shops.net/earth-science/Beaufort_Wind_Force_Poster.htm
A light-hearted look at scale of conflicts in bar-rooms (pubs) http://www.shulist.com/2009/01/shulist-scale-of-conflict/
M. L. Cummings: